Download Whitepaper
(pdf, 5 MB)


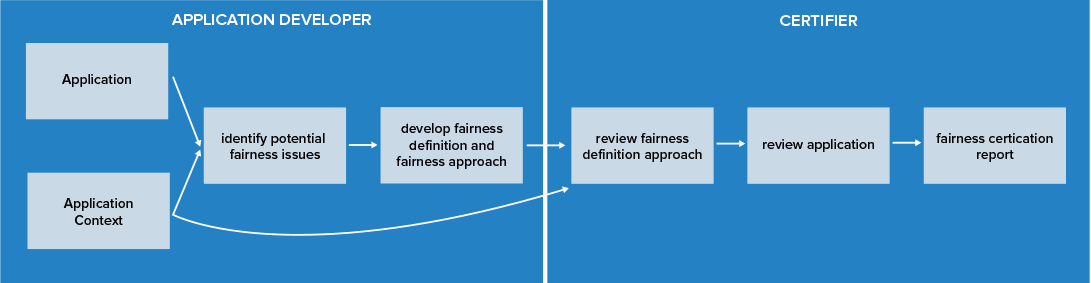
Measuring Fairness
In response to the rising awareness of AI-related fairness issues, the research community has developed a wide range of quantitative fairness and bias metrics10 many of which are already integrated open-source toolkits11,12,13,14, which assess group fairness, individual fairness or a balanced combination of the two. However, as evidenced by a large number of proposed and applied fairness metrics, there exists no single “ideal” fairness measure due to the challenge of defining fairness described above.
Equality-in-Outcome Approach
Statistical parity difference (spd) is a group-fairness measure defined as:
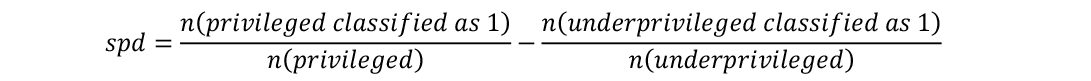
which can also be written as probabilities:
![]()
How exactly the distinction between privileged and underprivileged groups is made depends on the context of the application. spd compares the fractions of each group classified as 1 (a positive classification, meaning an invitation to a job interview in our hiring algorithm example). This comparison is independent of the group size. In this metric, perfect equality is reached at a value of zero, which means that the same fraction of people is chosen from both groups. For example, if 20% of the overall population are invited for a job interview, in order to be fair 20% of each group should be invited regardless of the group size. This is often described as a “we-are-all-equal” approach since it assumes that there is no difference between the groups even if there is a difference in the data. One main drawback of spd is that it does not address true or false classification of individuals.
Equality-in-Quality Approach
The average odds difference (aod) is another group fairness measure. In contrast to spd, it does not consider classifications as such (e.g., acceptance rates in our job application algorithm example) but rather the quality of the classifications and measures whether the quality rate defined via the false positive (the fraction that is incorrectly classified as 1) and the positive rate (the fraction that is correctly classified as 1) differs between the groups.
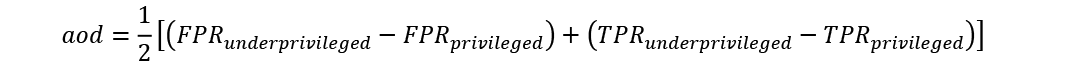
Perfect equality is indicated by a zero. This is often described as a “what-you-see-is-what-you-get” worldview since it does not assume that an equal fraction from all groups must be accepted, only that the quality of the predictions should be the same for each group. Under this approach, the algorithm can choose only a very small fraction of one of the groups as long as it corresponds to the underlying data. In other words, this approach assumes that the data itself is not biased and accurately reflects reality, ensuring that no bias is introduced by the AI algorithm.
Besides these two examples, there are many other fairness notions, such as conditional statistical parity, equal opportunity, fairness through unwareness, fairness through awareness and counterfactual fairness (https://arxiv.org/pdf/1908.09635v1.pdf).
Below is a summary of issues related to fairness of AI applications:
- There is no single concept of fairness.
- Definitions of fairness often contradict each other.
- Setting the boundary for fairness issues in an application is non-trivial and ambiguous.
- All of the above points are tightly coupled with ethical considerations and worldviews that depend on many factors, such as region and culture, and can change over time.
In the remaining part of this paper, we discuss how to overcome those obstacles when certifying AI applications in term of fairness.